2021 IEEE International Conference on Image Processing
19-22 September 2021 • Anchorage, Alaska, USA
Imaging Without Borders

There are 6 million car accidents in the US every year, the vast majority of which are caused by human error, including distraction and fatigue. Life-threatening episodes such as heart attacks also pose a serious threat. Additionally, humans seated in abnormal positions, such as having their legs on the dashboard, pose other safety concerns such as fatal injuries when airbags are deployed. To prevent these accidents and avoid dangerous situations in the vehicle, continuous and unobtrusive monitoring of vital signs and body poses have been proposed in the context of driver monitoring systems.
This demo presentation will first review recently proposed methods for heart rate estimation from camera measurements [1]–[3], including both signal processing and learning-based approaches to this problem. Several practical challenges to realize these techniques with high accuracy in commercial products will also be discussed, including the effects of sunlight and lighting variations, as well as the head motion of the human subject.
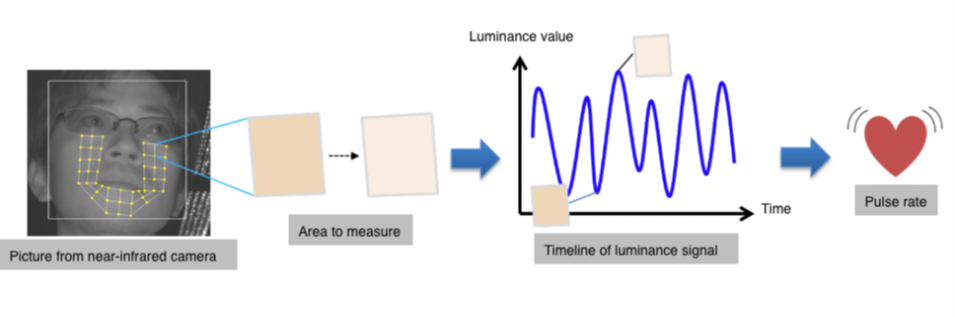
A simplified illustration of the technique, which is known as imaging photoplethysmography (iPPG), is shown in Figure 1. The method relies on measuring minuscule intensity variations of skin regions with each cardiac cycle, caused by varying blood volume over time. Considering the small intensity-based iPPG signal and the need to measure a stable and consistent signal over time, methods to deal with illumination variations and head motion are necessary.
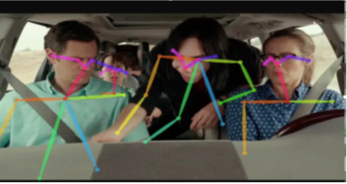
A second aspect of this demo presentation is to discuss challenges in detecting abnormal passenger poses as measured by in-vehicle cameras. Considering the difficulty in modeling the wide range of abnormal poses, a one-class classifier has been recently proposed to differentiate normal versus abnormal pose data [4]. Examples of out-of-pose positions from the recently released Dash-Cam-Pose dataset are shown in Figure 2.
While the technique in [4] has been shown to be effective for detecting in-position versus out of-position poses, it is often desirable for the system to classify specific types of abnormal positions or unsafe behaviors, such as the driver using a handheld phone or texting while the car is in motion. Enabling this level of precision would allow the vehicle to prompt the driver or passenger in a more specific and purposeful manner. The status of the work towards this goal will be discussed along with associated challenges, including precision of the pose estimation, handling of occlusions, and issues with data collection and labeling.

Video demonstrations of both heart rate estimation and out-of-position estimation will be provided, illustrating cases in which the system works well under challenging conditions as well as instances in which the system fails, highlighting the needs for future work in these areas. Additionally, we will outline other application domains in which the technology can be applied.
In this demo, we will introduce our elevated skin temperature screening solution, which helps us to keep our working environment safe during the pandemic.
There have been many EBT devices on the market recently, but many systems suffer from inaccurate measurements, inconvenient user experience, complicated setup, and high cost. The demoed system is completely mobile, easy to setup, user friendly, low cost, and most importantly highly accurate.
The system works entirely on a mobile platform running with Qualcomm Technologies chipset. It takes live video inputs from the on-device RGB camera and an external thermal camera and applies the in-house developed face detection and facial landmark detection algorithms to localize key facial regions on both RGB and thermal images for measuring temperature. The overall measurement process can be done with seconds. Study shows that the system can reliably measure body temperature at 1.5m with accuracy with ±0.3°C, achieving FDA’s standard for IR thermometers. Mask and glasses detection models are also applied to provide health-related warnings. Face recognition can also be integrated to the system to automatically enroll badges for security gate control.
The demo setup will include a tripod, a tablet with a (small) thermal camera attached. Each audience who would like to try the demo will be asked to stand about 1 meter away in front of the camera stand and will see their face and facial landmarks being detected on both RGB and thermal images, and their temperature being measured through the UI display.
Non-Destructive Testing (NDT) is a wide group of quantity control techniques used in manufacturing without causing damage. Radiographic Testing (RT) is one of the most widely adopted method to inspect material and components. It uses either X-ray or Gamma-ray to locate defects underneath materials, which is unattainable by visual inspection1. Hence RT plays a vital role in many manufacturing industries such as maritime, oil & gas and aerospace, etc.
In practice, RT film inspection process is composed of the following tasks: image Quality Indicator (IQI) test, recognition of defect type, quantitative standard evaluation, and records of inspection results. Each film needs reviews from multiple certified NDT specialists. The lack of experts and the human issues are the major challenges the RT industry.
In this demo, we will present an automatic digital solution to mitigate these problems. Our platform is based on the recent success of deep learning methods in object detection and segmentation.
Our solution consists of four parts:
As a user-oriented demo, we will explain and illustrate our platform on a web-based interface. It allows users to conveniently upload RT film images, automatically analyze defects alongside welding lines, print layouts for repair and generate RT reports. The demo will highlight efficient decision-making support for NDT specialist, and present its benefits to them.
At last, we find some practical topics in this area, which may be interested to the academic researchers. First, the tiny line set detection can be challenging for the general detection models. Second, the imbalance of different defect types is also a big challenge for segmentation, which leaves large room to further improvements. Joint efforts between academia and industry are expected in future.
AI is getting wider applications in edge systems. The models deployed to edges may not be able to swiftly adapt to the data pattern drift, which leads to growing degraded performance and require human intervention to update accordingly. Therefore, we design an Auto evolve process for machine learning Intelligence on Edge (AIoE), which leverages the available hardware resource across end to cloud to solve data drift problem. There are mainly 2 innovative parts in our demo:
The vision and sensing company trinamiX invented a unique technology, called Beam Profile Analysis, to extend computer vision from 2D- and 3D-sensing to material sensing. The necessary hardware consists of optical standard modules, including a laser dot projector, an illumination unit and a CMOS camera.
At the core of the innovation is a new class of algorithms, which provides features derived from the analysis of the two-dimensional intensity distribution of each projected laser spot. The physics of reflection offers a variety of detectable properties like diffuse scattering, direct reflection, volume scattering, absorption or interference effects. Furthermore, due to the convolution of the reflected laser beam with the camera lens prior to signal detection, a distance-dependent fingerprint information is included as well. We use our proprietary physics-inspired image processing filters and AI-based approaches to extract the distance and material information from the laser spot images.
The additional material information of the measured object adds value to multiple applications: face authentication for unlock or mobile payment becomes much more secure by verifying a person's liveness by recognizing its skin. Unauthorized access is prevented, and sensitive user data is protected. trinamiX provides a solution that is convenient to use and at the same time fulfills highest security standards as for example defined by FIDO. In combination with the fact, that the technology can be used behind an OLED display it also opens up opportunities to provide smartphones without the need for a notch or hole. Moreover, Driver Monitoring Systems in cars cannot only be enhanced by trinamiX technology but also hidden behind an OLED instrument board.
In the demo trinamiX will show how material detection capabilities can be used to differentiate between skin and typical mask materials, simulating a realistic spoof attempt. Furthermore, the performance of the depth map and the impact of an OLED in the optical pathway will be illustrated.
The sensor system comes with a python-based SDK to enable testing and evaluation by customers
The rapid increase in user-generated videos on smartphones raises the need for content management tools that can run on-device. The goal of this demo is to showcase a step towards retrieving relevant videos stored on a user-device. This system should be accurate, resource-efficient, and able to recognize a wide range of concepts that may appear in user videos including actions (e.g. swimming), objects (e.g. bicycle), scenes (e.g. beach), attributes (e.g. red), and events (e.g. party). While the development of image representation methods using Convolutional Neural Networks (CNN) has matured in recent years, there are multiple ways to represent a video. The first line of work represents each frame separately using powerful image-based CNNs and use methods like max-pooling, VLAD, Fisher Vector or sequential models like LSTMs to aggregate the frame-level features into a video-level feature. Some methods also use optical flow as another modality to capture motion information. Other line of work consider video as 2D+time dimensional data and uses 3D convolutional layers to jointly capture spatial and temporal information. Each of these representations comes with different computational cost and merits to model spatial and spatiotemporal information. Some are more accurate in capturing the temporal clues, which are crucial for recognizing activities, while some others are better in capturing spatial details such as background information. We extensively analyzed current state-of-the-art 2D and 3D models in terms of accuracy and efficiency on large-scale holistic video understanding benchmark. Our analysis demonstrates that simple strategies such as average pooling and using a mixture of experts is a hard baseline to beat. We also show that while sampling more frames increases performance, you can save a lot of compute while still retaining reasonable performance by sampling less. Based on these findings, we have implemented a very efficient and accurate video search system. It processes 133 seconds of video per second, on a 1080Ti GPU, with a precision@10 of 91.1%. The demo consists of three parts, video retrieval, offline localization, and online localization. Each part is visualized through webpages which allows the user to interact with the content. For retrieval we rank roughly 250000 videos which have been processed offline. The top 1000 videos for 10 concepts are shown in order with their human-annotated labels. The online localization page has a set of videos on which we show the top concepts that align with the content at different timesteps, we also show statistics such as inference speed here. The offline localization does the same but has the probabilities pre-computed.
Many solutions are available in the literature to reconstruct a 3D face. These may either require an additional depth sensor that incur extra costs while more recent algorithms apply complex deep learning networks with a single RGB image but may lack the realism needed for use cases like virtual reality. In addition, the available solutions are still computationally intensive to run in real-time on platforms with limited computational resources.
In this demo, we will introduce a Single Snapshot solution to generate a high-quality 3D Mesh of a face from a single Selfie RGB Image. The demoed system can generate a realistic 3D face model and can run in real-time on a mobile phone using Qualcomm Technologies chipset available in various commercial phones.
The system takes live video inputs from the on-device RGB camera and applies a developed face detection algorithm to localize a facial region. The system then processes the facial region to estimate a facial 3D morphable model on the fly using a in house fitting mechanism. This step will allow us to generate an initial coarse depth map of the face. The system finally applies a developed facial depth super resolution algorithm to resolve the facial details from both the coarser depth map and the input RGB image. This will let us obtain the high-quality facial mesh we desire.
The demo setup will include a mobile phone with Qualcomm® Snapdragon™ 888 chipset. Each person can see the face being reconstructed in real-time on the phone with over 30 frames per second end to end.
Autonomous mobile robots (AMR) are gaining popularity and use cases vary from factory and warehouses setup to outdoor last mile delivery. To successfully navigate through the environment, the robot relies on various sensors where an end to end pipeline will include various stages from sensors pre- processing, to perception, to simultaneous localization and mapping and grid occupancy, to trajectory planning and motion control. While LIDAR was typically used for SLAM and camera for perception, in recent years algorithmic advancements enabled using LIDAR for object detection, localization and classifications. Most of these algorithms are DNN based (i.e VoxelNet, pointpillars) with heavy compute requiring an accelerator. In addition, in various uses cases object detection can be done as a fusion between Lidar and camera while classification done using imaging.
Intel developed a CPU friendly LIDAR based object detection and localization algorithm (Patent Granted, No. 10,510,154). The algorithm uses a novel Adaptative DBSCAN (density-based spatial clustering of applications with noise) to detect arbitrary shapes by adaptively computing the number of points per cluster as well at the radius of the cluster, based on the distance from the LIDAR and the point cloud distribution, enabling efficient detection of objects at all ranges from the LIDAR sensor, in other words increasing the detection range of the LIDAR by 20-30% over state-of-the-art methods. The number of points are computed based on LIDAR data characteristic using a model fitting (min # of points vs Range). The number of data points in the cluster combined with input data statistics are used to derive the desired radius (i.e min radius in a hypersphere). The algorithm can be easily multithreaded to achieve > 100 fps on Intel robotics platform. The detected 3D clusters can be easily superimposed on image frame for classification if required.
At the conference, Intel will have a live demo using Intel robotics platform running an end to end wandering application using a ROS robotics stack integrating ADBSCAN showing the minimal CPU resources used by the algorithm and demonstrating the high accuracy at various ranges from the robot to detect and locate objects. The demo will require an open space in the venue where obstacles can be added and for the robot to navigate around. In addition, a display is required to show the CPU usage.
AI industry users like autonomous driving companies rely on enormous data and computation power. Managing the data, ML models and the underlying IT system is complex and expensive. HCI (Hyper-Converged Infrastructure) system helps alleviate the complexity issue, but conventional techniques like deduplication offers little help with storage cost. To solve these problems, we propose a system that can evolve the data into optimized set via steps of filtering, distillation, transformation and so on, to greatly reduce the data size at no/little cost to ML model performance, taking advantage of the integrated compute and storage system. We also validate our ideas using the data from ADAS cars, images collected by these cars are distilled from 30k to 3 finally, without impairing the performance of the model.
Overall, our solution is a tiered storage pool which could deal with data in an intelligent way, according to the AI and Law requirements. Concretely, our novelties and contributions are:
Proper rowing technique is essential for rowers. Efficiency, one significant component, for these athletes means creating a physical body that can perform exceptional endurance, strength, and power movements, all while maintaining proper rowing technique. Each rowing stroke motion has its temporal pattern due to the cyclic nature of rowing, which is perfect for automating sports biomechanical analysis with real-time pose estimation technique at the edge.
Rowing is a data rich sport, rowing data analytics is to understand more about elite level performance profile. The more the coaches understand about what the data tells them, the more they can combine it with their own expertise to make better, evidence-based decisions that improve training and competition performance.
In the edge computing scenario, we usually face many changing factors in the physical environment. Dedicated to the rowing team, they go to different cities and sites for training and competitions, requiring picking up and moving the portable, ruggedized edge devices from here to there. Moreover, the networking connection of indoor and on-water training venues cannot be guaranteed.
Motion capture technology and wearable devices have been widely used in sports. Such solutions, however, requiring fixed space, complicated device settings and frequent device calibration, are not practical for long-duration rowing technique workouts. In such a case, the edge intelligence solution has great potential to generate fast understandings and real-time insights with rowing technique workout data.
In the research work of Dell Olympic Aquatic Sports Lab established by Dell Technologies China and China Rowing Association & China Canoeing Association, an adaptive edge intelligence hierarchy solution is built to support various streaming data pipelines with low latency and generating actionable insights in real-time, including video motion detection workload, data analysis workload, visualization feedback workload of video detection results and data analysis results, and persistence workload for raw data, detection results and analysis results.
The live demo experience is, by capturing video streams of rower’s training workout on indoor rowing machine, the human pose is detected with deep learning models, then the stroke motion is generated with a group of continuous pose estimations, next sports biomechanical analysis is performed to discover insights on technical motions. We unlock the value of data such as stability, strength and intra-stroke fluctuations, generate precise technical motion evaluation and professional recommendations which are fed back to coaches and athletes with visualization in real-time. That is, the edge intelligence solution provides accurate data insights on rower’s technique workout, allowing them concentrate more on maintaining proper rowing technique, without any distractions.
The devices used in the live demo include indoor rowing machine, camera, Dell Precision mobile workstation and display.
Edge computing is an important pillar for IoT applications bringing the Cloud resources to the Edge, serving real-time applications, and reducing the computing and network resources required to transfer data for processing in the Cloud. Besides real-time analytics, edge Computing provides a unique value proposition for IoT applications through reduced latency, reduced cost, and improved data security. In Autonomous mobile robots (AMR) or surveillance cameras use cases, there is a need for workload orchestration between the multiple devices of diverse processing capabilities (e.g., robot-arm, autonomous mobile robot, depth camera,…). Intel converged edge solution with Open Network Edge Services Software (OpenNESS) enables cloud-native applications workload orchestration between edge nodes leveraging different telemetry information from the edge nodes.
In this demo, we demonstrate a use case for one or more AMRs forming a Kubernetes cluster with an OpenNESS edge node that provides intelligent resource-aware orchestration of the vision perception workload enabling adaptive and hybrid compute mode between the AMRs and the edge server. The live demo setup will have one or more Intel based mobile robots connected to the OpenNESS edge server and will demonstrate how using OpenNESS the server can perform operations like fleet management and compute offload of vision perception operations (such as object detection and classification) from the AMRs to the edge server. Intelligent offloading decision is considered based on the available resources on the AMR device and battery level, the framework may adapt
While the demo will focus on vision perception (as the most demanding workload), the same concept is applicable to other sensors (e.g., LiDAR).
There is active research on new image and video coding methods using neural networks (NNs), showing impressive compression performance while allowing friendly parallel implementation for real-time deployment. However, since NN implementations contain several new technologies and are computationally intensive, there has been questions about how they can be deployed using the limited computation and power resources of consumer devices, like mobile phones and tablets, and considering the high data throughputs required by HD video.
This demo presents our work done at Qualcomm Technologies, Inc. to study the steps needed to move from research-level Python code all the way down to implementations that can run in real time on current processors. The demo content is a NN decoder that can play HD video at 30 fps on a Qualcomm® Snapdragon™ SoC.
It is explained that this is achieved in two ways: (a) exploiting the powerful heterogeneous computing resources that are available in mobile devices, providing several elements optimized for NN computations and other tasks; (b) the Qualcomm® Neural Network development platforms and optimization tools, for tasks like quantization and compression of Neural Network weights, performance profiling, hardware-aware neural architecture search and quantization aware training.
Nowadays, the source of a high percentage of real-world data is video. Segmentation in videos enables many emerging mobile use cases, including autonomous driving, phones, cameras, and AR/VR applications. However, running segmentation on high-resolution video on mobile phones in real-time is challenging due to its high computation cost, memory bandwidth demand, and energy consumption. In this demo, we showcase our efficient video segmentation approach to process high-resolution video streams on a Qualcomm Technologies mobile device in real-time. Given a state-of-the-art semantic segmentation network trained by our newly developed training loss (CVPR21 oral), Step-1 applies hardware-aware channel adjustment that prunes away a fraction of the total channels to fit the hardware preference best. Step-2 reduces computational load cost by inserting a pair of down-sample and up-sample layers into the network. Step-3 converts the network to a spatiotemporal network while taking into account both space and time characteristics of the video. The previous frame’s features are carried over to the current frame in a compact form to allow the network to take advantage of temporal information. The last step applies a training method that utilizes both labeled and unlabeled data for better training results and better use of abundant unlabeled images. The outcome is the efficient video segmentation network called as EVSNet. We use a high-resolution video in this demo (2048 by 1024 RGB video). The output is one of 19 class labels for each input pixel. Our approach reduces the computational load from 78 GMACs down to 17 GMACs. At the same time, the mean intersection-over-union (mIoU), a key measure of accuracy, only drops one-tenth of a percent. We show performance indicators collected from phones powered by the latest Qualcomm® Snapdragon™ Mobile Platform. In addition, the inference throughput increases from 14 frames per second to 39 frames per second. The amount of memory read-and-write operations significantly reduces on our mobile platform. We demonstrate side-by-side comparisons between our improved network and a recent segmentation model running on our mobile platform for the video semantic segmentation task. Our improved network runs in real-time on 2K video and achieves SOTA performance.